

Pandasql If you can add only one skill—and inarguably the most important—to your data science toolbox, it is SQL. In the Python data analysis ecosystem, however, pandas is a powerful and popular library.
But, if you are new to pandas, learning your way around pandas functions—for grouping, aggregation, joins, and more—can be overwhelming. It would be much easier to query your dataframes with SQL instead. The pandasql library lets you do just that!
So let’s learn how to use the pandasql library to run SQL queries on a pandas dataframe on a sample dataset.
First Steps with Pandasql
Before we go any further, let’s set up our working environment.
Installing pandasql
- If you’re using Google Colab, you can install pandasql using
pipand code along:
pip install pandasql
If you’re using Python on your local machine, ensure that you have pandas and Seaborn installed in a dedicated virtual environment for this project. You can use the built-in venv package to create and manage virtual environments.
I’m running Python 3.11 on Ubuntu LTS 22.04. So the following instructions are for Ubuntu (should also work on a Mac). If you’re on a Windows machine, follow these instructions to create and activate virtual environments.
To create a virtual environment (v1 here), run the following command in your project directory:
python3 -m venv v1
Then activate the virtual environment:
source v1/bin/activate
Now install pandas, seaborn, and pandasql:
pip3 install pandas seaborn pandasql
Note: If you don’t already have pip installed, you can update the system packages and install it by running: apt install python3-pip.
The sqldf Function
To run SQL queries on a pandas dataframe, you can import and use sqldf with the following syntax:
from pandasql import sqldf
sqldf(query, globals())
Here,
- query represents the SQL query that you want to execute on the pandas dataframe. It should be a string containing a valid SQL query.
- globals() specifies the global namespace where the dataframe(s) used in the query are defined.
Querying a Pandas DataFrame with Pandasql
Let’s start by importing the required packages and the sqldf function from pandasql:
import pandas as pd
import seaborn as sns
from pandasql import sqldf
Because we’ll run several queries on the dataframe, we can define a function so we can call it by passing in the query as the argument:
#Define a reusable function for running SQL queries
run_query = lambda query: sqldf(query, globals())
For all the examples that follow, we’ll run the run_query function (that uses sqldf() under the hood) to execute the SQL query on the tips_df dataframe. We’ll then print out the returned result.
Loading the Dataset
For this tutorial, we’ll use the “tips” dataset built into the Seaborn library. The “tips” dataset contains information about restaurant tips, including the total bill, tip amount, gender of the payer, day of the week, and more.
Lload the “tip” dataset into the dataframe tips_df:
Load the “tips” dataset into a pandas dataframe
tips_df = sns.load_dataset(“tips”)
Example 1 – Selecting Data
Here’s our first query—a simple SELECT statement:
Simple select query
query_1 = “””
SELECT *
FROM tips_df
LIMIT 10;
“””
result_1 = run_query(query_1)
print(result_1)
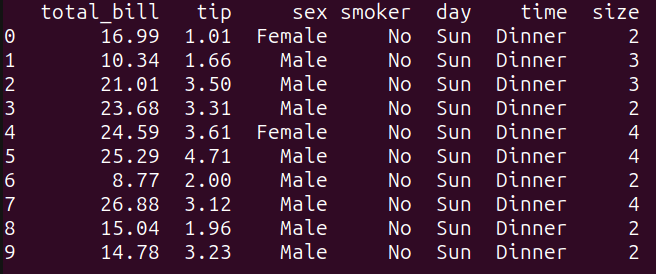
As seen, this query selects all the columns from the tips_df dataframe, and limits the output to the first 10 rows using the LIMIT keyword. It is equivalent to performing tips_df.head(10) in pandas:
Example 2 – Filtering Based on a Condition
Next, let’s write a query to filter the results based on conditions:
# filtering based on a condition
query_2 = """
SELECT *
FROM tips_df
WHERE total_bill > 30 AND tip > 5;
"""
result_2 = run_query(query_2)
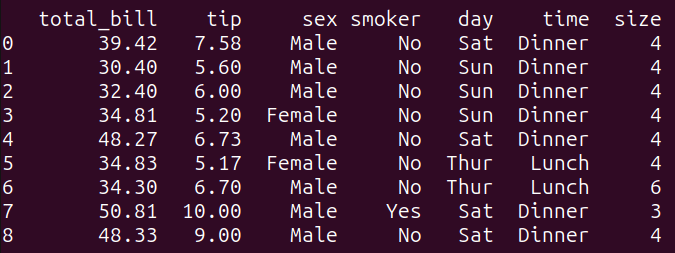
print(result_2)This query filters the tips_df dataframe based on the condition specified in the WHERE clause. It selects all columns from the tips_df dataframe where the ‘total_bill’ is greater than 30 and the ‘tip’ amount is greater than 5.
Running query_2 gives the following result:
Example 3 – Grouping and Aggregation
Let’s run the following query to get the average bill amount grouped by the day:
# grouping and aggregation
query_3 = """
SELECT day, AVG(total_bill) as avg_bill
FROM tips_df
GROUP BY day;
"""
result_3 = run_query(query_3)
print(result_3)Here’s the output:

We see that the average bill amount on weekends is marginally higher.
Let’s take another example for grouping and aggregations. Consider the following query:
query_4 = """
SELECT day, COUNT(*) as num_transactions, AVG(total_bill) as avg_bill, MAX(tip) as max_tip
FROM tips_df
GROUP BY day;
"""
result_4 = run_query(query_4)
print(result_4)The query query_4 groups the data in the tips_df dataframe by the ‘day’ column and calculates the following aggregate functions for each group:
num_transactions: the count of transactions,avg_bill: the average of the ‘total_bill’ column, andmax_tip: the maximum value of the ‘tip’ column.
As seen, we get the above quantities grouped by the day:

SQL in Pandas with Pandasql
Want to query your pandas dataframes using SQL? Learn how to do so using the Python library Pandasql.
By Bala Priya C, KDnuggets on October 4, 2023 in SQL
FacebookTwitterLinkedInRedditEmailShare

Image by Author
If you can add only one skill—and inarguably the most important—to your data science toolbox, it is SQL. In the Python data analysis ecosystem, however, pandas is a powerful and popular library.
But, if you are new to pandas, learning your way around pandas functions—for grouping, aggregation, joins, and more—can be overwhelming. It would be much easier to query your dataframes with SQL instead. The pandasql library lets you do just that!
So let’s learn how to use the pandasql library to run SQL queries on a pandas dataframe on a sample dataset.
First Steps with Pandasql
Before we go any further, let’s set up our working environment.
Installing pandasql
If you’re using Google Colab, you can install pandasql using `pip` and code along:
pip install pandasqlIf you’re using Python on your local machine, ensure that you have pandas and Seaborn installed in a dedicated virtual environment for this project. You can use the built-in venv package to create and manage virtual environments.
I’m running Python 3.11 on Ubuntu LTS 22.04. So the following instructions are for Ubuntu (should also work on a Mac). If you’re on a Windows machine, follow these instructions to create and activate virtual environments.
To create a virtual environment (v1 here), run the following command in your project directory:
python3 -m venv v1Then activate the virtual environment:
source v1/bin/activateNow install pandas, seaborn, and pandasql:
pip3 install pandas seaborn pandasqlNote: If you don’t already have `pip` installed, you can update the system packages and install it by running: apt install python3-pip.
The `sqldf` Function
To run SQL queries on a pandas dataframe, you can import and use sqldf with the following syntax:
from pandasql import sqldf
sqldf(query, globals())Here,
queryrepresents the SQL query that you want to execute on the pandas dataframe. It should be a string containing a valid SQL query.globals()specifies the global namespace where the dataframe(s) used in the query are defined.
Querying a Pandas DataFrame with Pandasql
Let’s start by importing the required packages and the sqldf function from pandasql:
import pandas as pd
import seaborn as sns
from pandasql import sqldfBecause we’ll run several queries on the dataframe, we can define a function so we can call it by passing in the query as the argument:
# Define a reusable function for running SQL queries
run_query = lambda query: sqldf(query, globals())For all the examples that follow, we’ll run the run_query function (that uses sqldf() under the hood) to execute the SQL query on the tips_df dataframe. We’ll then print out the returned result.
Loading the Dataset
For this tutorial, we’ll use the “tips” dataset built into the Seaborn library. The “tips” dataset contains information about restaurant tips, including the total bill, tip amount, gender of the payer, day of the week, and more.
Lload the “tip” dataset into the dataframe tips_df:
# Load the "tips" dataset into a pandas dataframe
tips_df = sns.load_dataset("tips")Example 1 – Selecting Data
Here’s our first query—a simple SELECT statement:
# Simple select query
query_1 = """
SELECT *
FROM tips_df
LIMIT 10;
"""
result_1 = run_query(query_1)
print(result_1)As seen, this query selects all the columns from the tips_df dataframe, and limits the output to the first 10 rows using the `LIMIT` keyword. It is equivalent to performing tips_df.head(10) in pandas: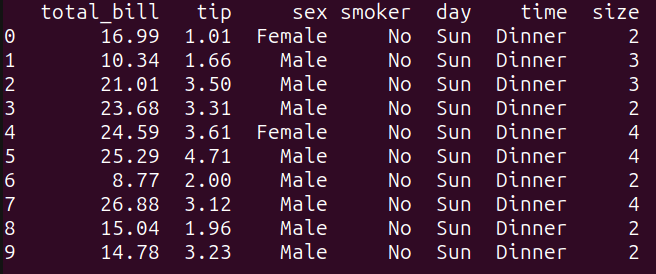
Output of query_1
Example 2 – Filtering Based on a Condition
Next, let’s write a query to filter the results based on conditions:
# filtering based on a condition
query_2 = """
SELECT *
FROM tips_df
WHERE total_bill > 30 AND tip > 5;
"""
result_2 = run_query(query_2)
print(result_2)This query filters the tips_df dataframe based on the condition specified in the WHERE clause. It selects all columns from the tips_df dataframe where the ‘total_bill’ is greater than 30 and the ‘tip’ amount is greater than 5.
Running query_2 gives the following result: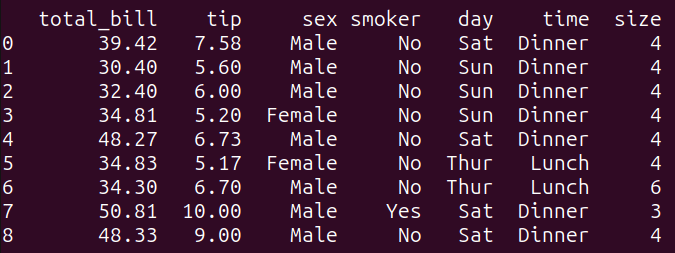
Output of query_2
Example 3 – Grouping and Aggregation
Let’s run the following query to get the average bill amount grouped by the day:
# grouping and aggregation
query_3 = """
SELECT day, AVG(total_bill) as avg_bill
FROM tips_df
GROUP BY day;
"""
result_3 = run_query(query_3)
print(result_3)Here’s the output: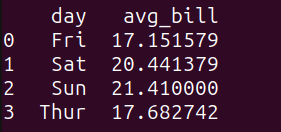
Output of query_3
We see that the average bill amount on weekends is marginally higher.
Let’s take another example for grouping and aggregations. Consider the following query:
query_4 = """
SELECT day, COUNT(*) as num_transactions, AVG(total_bill) as avg_bill, MAX(tip) as max_tip
FROM tips_df
GROUP BY day;
"""
result_4 = run_query(query_4)
print(result_4)The query query_4 groups the data in the tips_df dataframe by the ‘day’ column and calculates the following aggregate functions for each group:
num_transactions: the count of transactions,avg_bill: the average of the ‘total_bill’ column, andmax_tip: the maximum value of the ‘tip’ column.
As seen, we get the above quantities grouped by the day: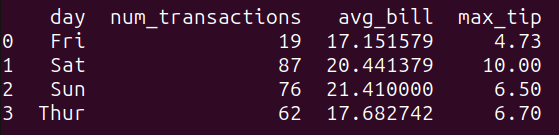
Output of query_4
Example 4 – Subqueries
Let’s add an example query that uses a subquery:
# subqueries
query_5 = """
SELECT *
FROM tips_df
WHERE total_bill > (SELECT AVG(total_bill) FROM tips_df);
"""
result_5 = run_query(query_5)
print(result_5)Here,
- The inner subquery calculates the average value of the ‘total_bill’ column from the
tips_dfdataframe. - The outer query then selects all columns from the
tips_dfdataframe where the ‘total_bill’ is greater than the calculated average value.
Running query_5 gives the following:

Example 5 – Joining Two DataFrames
We only have one dataframe. To perform a simple join, let’s create another dataframe like so:
# Create another DataFrame to join with tips_df
other_data = pd.DataFrame({
'day': ['Thur','Fri', 'Sat', 'Sun'],
'special_event': ['Throwback Thursday', 'Feel Good Friday', 'Social Saturday','Fun Sunday', ]
})The other_data dataframe associates each day with a special event.
Let’s now perform a LEFT JOIN between the tips_df and the other_data dataframes on the common ‘day’ column:
query_6 = """
SELECT t.*, o.special_event
FROM tips_df t
LEFT JOIN other_data o ON t.day = o.day;
"""
result_6 = run_query(query_6)
print(result_6)Here’s the result of the join operation:

Wrap-Up and Next Steps
In this tutorial, we went over how to run SQL queries on pandas dataframes using pandasql. Though pandasql makes querying dataframes with SQL super simple, there are some limitations.
The key limitation is that pandasql can be several orders slower than native pandas. So what should you do? Well, if you need to perform data analysis with pandas, you can use pandasql to query dataframes when you are learning pandas—and ramping up quickly. You can then switch to pandas or another library like Polars once you’re comfortable with pandas.